コラムカテゴリー:DX(デジタル・トランスフォーメーション), ITコンサルティング, 技術
記事の執筆

田中 直
前職ではシステム改善・開発の提案から要件定義、設計、プログラミング、試験、運用サポートまで、プロジェクトの全工程に従事していたが、より上流工程に特化してクライアントへ直接的に貢献したいとの思いから、ASCへ入社する。ASC入社後は、前職での豊富なシステム開発経験・知識に加えて中小企業診断士としての知見を活かし、経営的な視点も踏まえたシステムコンサルタントとして活躍している。
生成AIにおけるRAGとは何か
RAGとは
RAGとは、Retrieval-Augmented Generationの頭文字を取った略称で、日本語では「検索拡張生成」のように訳されます。
生成AI(※)がユーザーの質問に回答する際に、大規模言語モデル(LLM)に任意のデータに対する検索機能を組み合わせて回答を出力する仕組みです。
※広義の生成AIには画像、音声生成AIや新しいものを生み出す仕組み自体を含みますが、その中でもRAGはテキストを理解、生成するAIの中核モデルであるLLM(Large Language Model)に特化した仕組みです。今回のコラムでは生成AI=LLMとして読み進めてください。
<Youtube版はこちら>
従来(RAGではない 非RAG)の生成AIとの違い
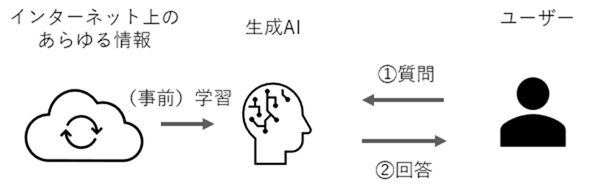
非RAGの生成AI利用イメージ
従来の生成AIでは事前に学習済のデータのみから回答を生成します。
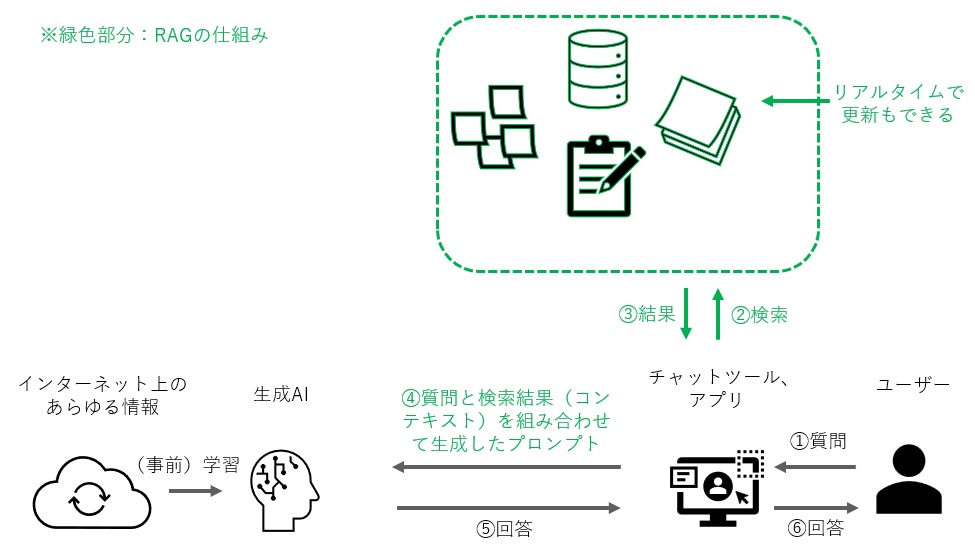
RAGを取り入れた生成AI利用イメージ
RAGを利用すると生成AIに扱わせたいデータを指定でき、さらにリアルタイムでコントロールすることができます。
従来の生成AIの問題点とは?問題が発生する事例
従来の生成AIには以下のような問題点があるとされています。
情報の古さ
学習時点の情報しか知らないため、最新の情報をインプットして再度学習させなければ反映されない
(例)ChatGPT(2024年版)に「日本の首相は誰?」と聞いたとき、モデルの学習が2023年で止まっていると、「岸田文雄」と答える
ハルシネーション(もっともらしい誤情報)
LLMは知らない情報でも”一般的にありそうな答え”を生成してしまうことがあります。
(例)「企業のパワハラを無くすための対策をパワハラ防止法の第5条(※)を引用して説明して」と、存在しない情報(※実際にはパワハラ防止法とは労働施策総合推進法の30条に盛り込まれた内容の通称)を質問すると、「第5条では、企業は年1回ハラスメント講習を義務づけている」などとありそうな回答を創作することがある
再現性が低い(回答が毎回ブレる)
同じ質問でも回答が微妙に変わり、根拠が明示されないためなぜその答えになったのかも検証できません。
(例)社内FAQで「育児休業の申請方法は?」と質問すると、1回目は「人事部にメールで申請」2回目は「専用システムから申請」と回答され、どちらもありそうだが正しいルールが保証できない
専門性・正確性に欠ける
LLMは一般知識には強いのですが、専門分野(法務・医療・金融など)では曖昧な回答をしてしまうことがあります。
(例)法律相談AIに「労働契約法第16条の趣旨を説明して」と聞くと、それっぽい説明を生成するが、条文を直接参照していないため誤解を含む
生成AIの問題点をRAGでどのように解決できるか
従来(非RAG)の生成AIとRAGを利用した生成AIの違いの例を挙げると以下のようになります。
| 非RAG | RAG | |
|---|---|---|
| 社内FAQチャットボット | LLM(GPTなど)が学習済み知識だけで回答する
↓
「一般的には、就業規則はこうです」など、一般論ベース |
LLMが質問内容から社内ドキュメント(PDF・規程集など)を検索して参照する
↓
自社の文書に基づく、正確で更新可能な回答 |
| 法律相談チャット | LLMが過去の一般知識だけで回答する
↓
「一般的には○○法の第△条が関係します」だが、古い可能性あり |
最新の法令データベースを検索し、該当条文を読み込んで回答する
↓
「改正後の○○法第△条では、〜と定められています」と正確に回答 |
| 商品検索アシスタント | LLMが一般的な情報だけで回答する
↓
「人気のスマホはiPhoneです」など、店舗在庫や価格情報は当然知らない |
外部APIやデータベースから商品情報を取得して回答する
↓
「在庫あり。○○店で128,000円です」とリアル情報を返す |
RAGが従来の生成AIの問題点を解決し、”リアルタイム性”と”具体性・正確性”をもたらすことがおわかり頂けましたでしょうか。
ファインチューニングでは解決できないのか
同じように生成AIの問題点を解決する方法の一つにファインチューニングという技術もあります。
公開されている学習済のモデルに、独自のデータを追加で学習させ、新たな知識を蓄えたモデルを作り出す技術です。
今回のコラムではRAGを中心に説明しているため深くは掘り下げませんが、ファインチューニングでは学習させるための大量の教師データや計算リソースが必要となりコストも時間も多くかかると言われています。
専門知識や専門分野に特化したモデルを構築する場合にはファインチューニングの方が適しているケースもあったり、RAGとファインチューニングを組み合わせるという選択肢もあるため、ファインチューニングでは生成AIの問題点を解決できない、というわけではありません。
RAGを取り入れることで生成AIを利用できるシーンが広がる
RAGでは上述したように従来の生成AIの問題点を防ぐことができるため、正確性が要求されるビジネスシーンにも活かせる可能性が高まると考えられます。
これまでリアルタイム性や正確性の問題により自社の業務への生成AI導入を躊躇していた企業でも今後は当たり前のように業務に生成AIを利用する時代が来るのではないでしょうか。
RAGを利用した生成AIの導入ステップ
RAGを利用した生成AIの導入ステップを図示すると以下のようになります。

最初から全社・全業務での導入を進めるのは費用や期間もかかることと、想像と違ったという失敗のリスクも増すため、小規模な人事・総務などのFAQ領域からスタートし、成功例や勘所を蓄積した上で他部署、他業務へ拡大していくのが成功の鍵となるのではないでしょうか。
弊社でもサービスとして提供している「DXコンサルティング」や「AIアドバイザリーサービス」の一環として、RAGを使った生成AI・AIエージェントなどのご提案にも取り組み始めておりますので、ご興味がある企業様は一度ご相談としてでもお声がけくださると幸いです。
関連サービス
2025年10月16日 (木)
青山システムコンサルティング株式会社
